

-


求职秘籍
站-
热门城市 全国站>
-
其他省市
-
-

 15692118659
15692118659
摘要:一个Application和一个SparkContext相关联,每个Application中可以有一个或多个Job,可以并行或者串行运行 Job。Spark中的一个Action可以触发一个Job的运行。在Job里面又包含了多个Stage,Stage是以Shuffle进行划分的。在 Stage中又包含了多个Task,多个Task构成了Task Set。
spark的结构图如下:
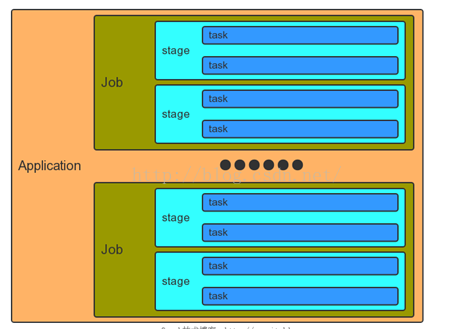
一个Application和一个SparkContext相关联,每个Application中可以有一个或多个Job,可以并行或者串行运行 Job。Spark中的一个Action可以触发一个Job的运行。在Job里面又包含了多个Stage,Stage是以Shuffle进行划分的。在 Stage中又包含了多个Task,多个Task构成了Task Set。
Mapreduce中的每个Task分别在自己的进程中运行,当该Task运行完的时候,该进程也就结束了。和Mapreduce不一样的是,Spark中多个Task可以运行在一个进程里面,而且这个进程的生命周期和Application一样,即使没有Job在运行。
这个模型有什么好处呢?可以加快Spark的运行速度!Tasks可以快速地启动,并且处理内存中的数据。但是这个模型有的缺点就是粗粒度的资源管理,每个Application拥有固定数量的executor和固定数量的内存。
Spark VS Hadoop有哪些异同点?
Hadoop:分布式批处理计算,强调批处理,常用于数据挖掘、分析
Spark:是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速, Spark是一种与 Hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark是在 Scala语言中实现的,它将 Scala用作其应用程序框架。与 Hadoop不同,Spark和 Scala能够紧密集成,其中的 Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop的补充,可以在 Hadoop 文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。Spark由加州大学伯克利分校 AMP实验室 (Algorithms,Machines,and People Lab)开发,可用来构建大型的、低延迟的数据分析应用程序。
虽然 Spark与 Hadoop有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟.
在大数据处理方面相信大家对hadoop已经耳熟能详,基于GoogleMap/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map,filter, flatMap,sample, groupByKey,reduceByKey, union,join, cogroup,mapValues, sort,partionBy等多种操作类型,他们把这些操作称为Transformations。同时还提供Count,collect,reduce, lookup, save等多种actions。这些多种多样的数据集操作类型,给上层应用者提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的分区等。可以说编程模型比Hadoop更灵活.
Spark解决了hadoop的哪些问题呢?
1.抽象层次低,需要手工编写代码来完成,使用上难以上手。
=》基于RDD的抽象,实数据处理逻辑的代码非常简短。
2.只提供两个操作,Map和Reduce,表达力欠缺。
=》提供很多转换和动作,很多基本操作如Join,GroupBy已经在RDD转换和动作中实现。(而hadoop完全需要自己实现,spark的scala都已经封装好了)。
3.一个Job只有Map和Reduce两个阶段,复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
=》一个Job可以包含RDD的多个转换操作,在调度时可以生成多个阶段(stage),而且如果多个map操作的RDD分区不变,是可以放在同一个Task中进行。
4.处理逻辑隐藏在代码细节中,没有整体逻辑
=》在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。代码不包含具体操作的实现细节,逻辑更清晰。
5.中间结果也放在HDFS文件系统中
=》中间结果放在内存中,内存放不下了会写入本地磁盘,而不是HDFS。
6.ReduceTask需要等待所有MapTask都完成后才可以开始
=》分区相同的转换构成流水线放在一个Task中运行,分区不同的转换需要Shuffle,被划分到不同的Stage中,需要等待前面的Stage完成后才可以开始。
7.时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够。
=》通过将流拆成小的batch提供Discretized Stream处理流数据。
8.对于迭代式数据处理性能比较差
=》通过在内存中缓存数据,提高迭代式计算的性能。
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。

 喜欢 | 1
喜欢 | 1
 不喜欢 | 0
不喜欢 | 0








您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式AI+学习就业服务平台 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号








 资料领取
资料领取

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




